
Data Structure를 이해해보자!
학습 목표 : Data Structure를 이해해보자!
자료구조란?
큰 데이터를 효율적으로 저장하고 꺼내기 쉽게 만드는 것을 의미한다.
즉, 데이터를 꺼내쓰기 쉽게 잘 정리 정돈하는 것
자료구조의 종류
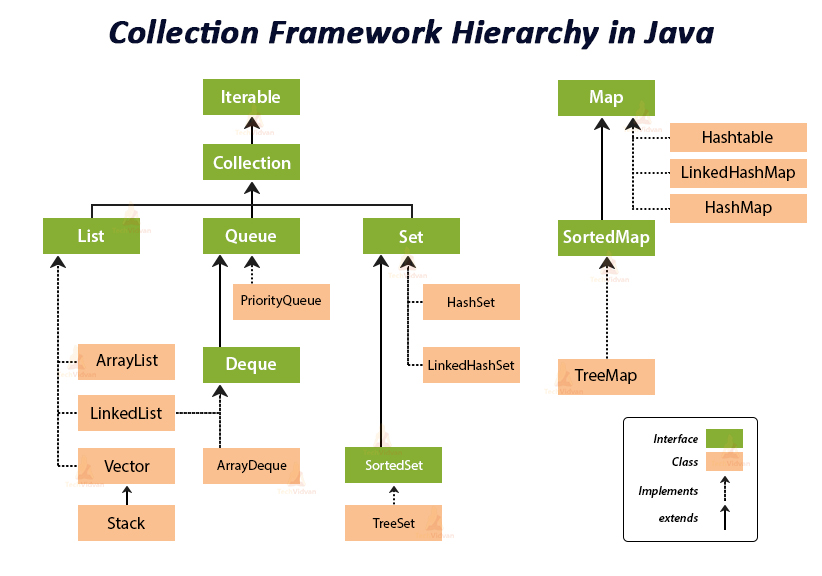
https://techvidvan.com/tutorials/java-collection-framework/
- Array
- List
- Tree
- Hash
내장 Data Structure
언어들이 중요한 Data Structure를 기본적으로 제공하고 있다. (제공하는 종류는 다 다르다)
API : 언어별로 내장된 데이터 스트럭처의 사용법
자바에서는 배열과 리스트를 따로 지원한다.
자료구조를 배우는 이유
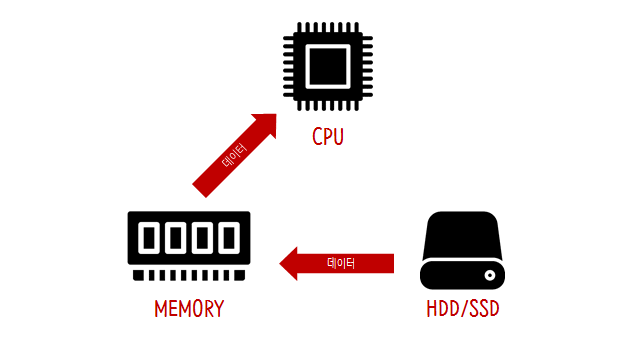
컴퓨터의 동작 원리
-
속도 , 가격
CPU > Memory(RAM) > HDD/SSD(Storage)
-
용량
HDD/SSD > Memory > CPU
데이터는 기본적으로 storage에 저장된다. 하지만 스토리지는 매우 느리기 때문에 어떤 프로그램을 실행하면 그 프로그램과 데이터는 Memory로 옮겨진다. CPU는 메모리에 로드된 데이터를 이용해 여러가지 일을 처리한다.
결국, 실행속도를 결정하는 건 대체로 메모리이므로 데이터스트럭처의 대상이된다. Data Structure를 배우는 이유는 빠른 속도를 위해 메모리를 효율적으로 사용하기위함이다.
메모리(RAM)
Random Access Memory로
메모리의 주소가 가리키는 위치에 각각의 데이터가 저장되어있다. 각각의 주소에 접근할 때 걸리는 시간이 동일하기 때문에 데이터가 저장된 위치 주소를 알고있다면 빠르게 데이터를 가지고올 수 있다.
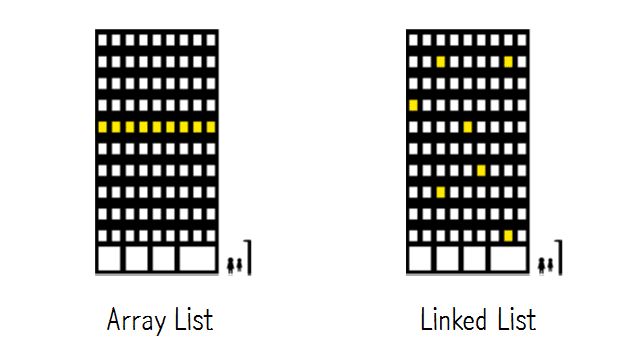
ArrayList
데이터들이 연속적으로 붙어서 저장된다.
LinkedList
데이터들이 흩어져서 저장되지만 각각의 데이터들은 연결되어있다.
자바에서의 Array
다수의 데이터를 그룹핑해서 효율적으로 관리할 수 있는 Data Structure이다.
int[] numbers = {10,20,30,40,50};
데이터가 많아지면 그룹관리의 필요성이 생긴다. 이 때 사용하는 것이 배열이다.
반복문으로 주로 데이터를 처리하는데, Data Structure는 복수의 데이터를 저장하는 일정의 저장소이고 복수의 데이터를 일괄적으로 처리하려면 반복작업이 필수적이기 때문이다.
- 하나의 요소를 엘리먼트라고 부른다
- 인덱스를 이용한 데이터를 조회가 빠르다.
- 하지만 어떤 엘리먼트가 삭제되면 삭제된 상태를 빈 공간으로 남겨둬야 한다. 이는 메모리 낭비를 초래한다.
자바에서의 List
데이터가 순서대로 저장되고, 중복이 허용되는 데이터모임이다.
- List가 지원하는 기능
- 처음, 끝, 중간의 엘리먼트를 추가/삭제
- 데이터가 있는지 체크
- 모든 데이터에 접근
1. ArrayList
배열을 이용해서 리스트를 구현한 것을 의미한다.
- 인덱스를 이용해 데이터를 가져오는 작업이 빈번한 경우 효율적인 방식이다. → ‘인덱스’로 접근
사용법
import java.util.ArrayList;
//생성
ArrayList<Integer> numbers = new ArrayList<>();
//맨 끝에 추가
numbers.add(10); //(값)
numbers.add(20);
numbers.add(30);
numbers.add(40);
//특정 위치에 추가
numbers.add(1,50); //(인덱스 , 값)
//삭제
numbers.remove(2); //(인덱스)
//가져오기
numbers.get(2); //(인덱스)
//데이터의 크기
numbers.size();
//해당 값의 인덱스
numbers.indexOf(30); //(값)
동작방식
-
엘리먼트의 추가
처음이나 중간에 저장하면 이후의 데이터들은 한칸씩 뒤로 물러나야한다.
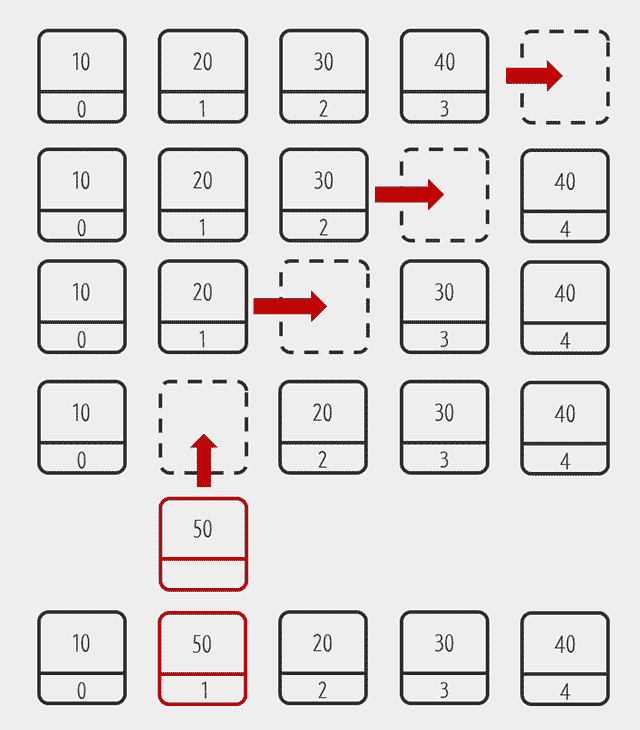
-
엘리먼트의 삭제
빈자리가 생기면 자리를 채우기 위해 순차적으로 한칸씩 땡겨온다.
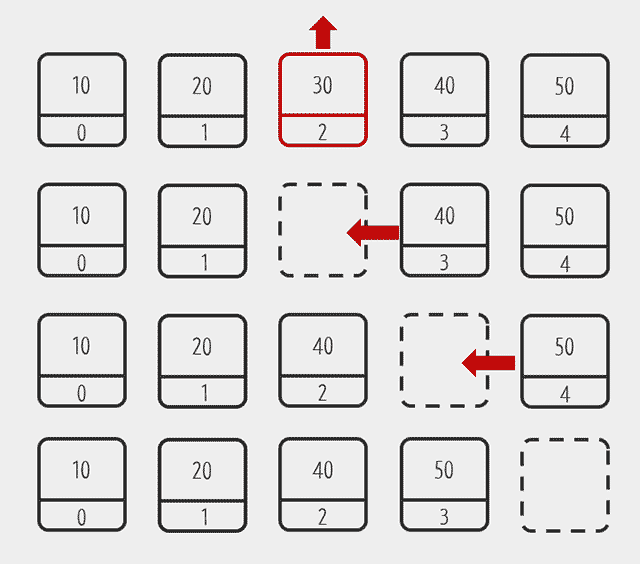
Iteration - 반복
- Iterator : ArrayList객체 내부에 저장된 값을 하나씩 순회하며 탐색할 수 있도록 돕는 객체이다.
- hasNext() : 가져올 수 있는 엘리먼트가 있는지 여부를 확인한다. → true/ false로 반환
- next() : 이 메서드를 호출할 때마다 엘리먼트를 순서대로 리턴한다.
Iterator<Integer> it = numbers.iterator();
//방식 1
while(it.hasNext()){
int value = (int)it.next();
// Object로 반환되기 때문에 int로 형변환해준다.
if(value == 30){
it.remove();
//it.next()를 통해 반환된 numbers의 엘리먼트를 삭제한다.
it.add();
//엘리먼트를 추가한다.
}
}
//방식 2
for(int value : numbers){
System.out.println(value);
}
//방식 3
for(int i = 0; i < numbers.size(); i++){
System.out.println(numbers.get(i));
}
2. LinkedList
노드(엘리먼트)와 노드간의 연결(link)을 이용해서 리스트를 구현한 것을 의미한다.
- 데이터의 추가/삭제가 빈번한 경우 효율적인 방식이다. → ‘순서’로 접근
구조 / 구성요소
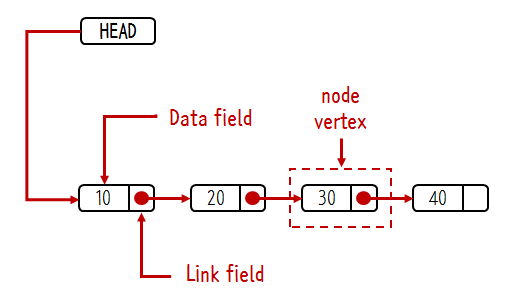
- 하나의 요소를 node(마디,교점) 또는 vertex(정점,꼭짓점)라고 부른다.
- 자바에서는 객체를 이용해 node를 표현한다 → node객체 안에 데이터 필드와 링크 필드를 만든다.
- Data field : 실제 값이 저장되는 곳(value 변수)
- Link field : 다음 노드의 정보가 저장되는 곳(next 변수) /(다음 노드의 포인터나 참조값을 저장하여 노드와 노드를 연결시킨다.)
- HEAD(first) : 첫번째 데이터가 무엇인지에 대한 정보를 가지고 있는 아이다.(첫번째 노드를 가리킨다)
동작 방식
노드 추가
- 시작 부분에 추가
- 새로운 노드를 생성
Node temp = new Vertex(input);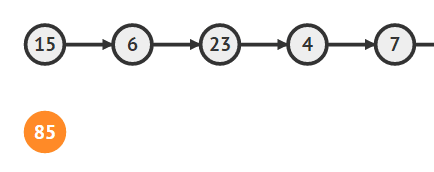
-
새로운 노드의 다음 노드로 첫번째 노드를 가리킨다.
temp.next = head; -
새로 만들어진 노드가 첫번째 노드가 되도록 head의 값을 변경한다.
head = temp;
-
중간 부분에 추가

-
첫번째 노드를 변수에 담기

Node temp1 = head; -
추가하려는 index 이전 노드(6)를 찾아서 temp1에 담기

int index; while(--k != 0){ temp1 = temp1.next; } -
추가하려는 index 다음 노드(23)를 찾아서 temp2에 담기

temp2 = temp1.next; -
추가할 노드 생성
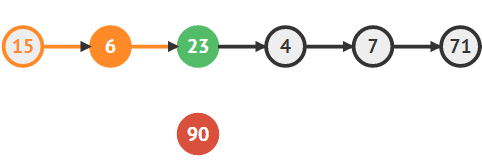
Node newNode = new Node(input); -
6의 다음 노드로 새로운 노드를 지정한다.
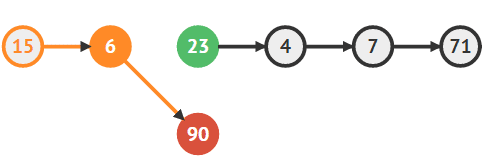
temp1.next = newNode; -
새로운 노드의 다음 노드로 23번을 지정한다.
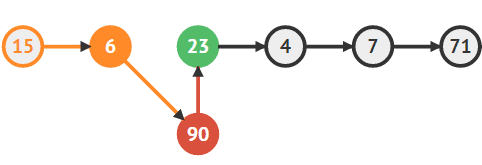
newNode.next = temp2;
-
노드 삭제
-
첫번째 노드를 변수에 담기
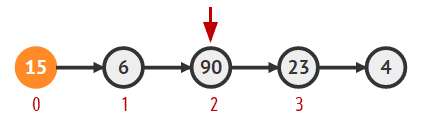
Node = head; -
삭제하려는 노드의 이전 노드 담기

while(--k != 0){ cur = cur.next; } -
삭제하려는 노드로 담기

Node todoDeleted = cur.next; -
이전노드의 다음노드를 이후노드로 지정
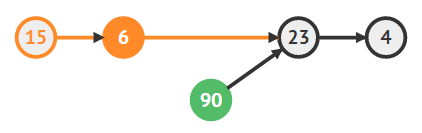
cur.next = todoDeleted.next; -
삭제하려는 노드 삭제하기
todoDeleted = null;
노드 조회 - 인덱스 이용
-
첫번째 노드를 변수에 담기
Node temp = head; -
몇번째 엘리먼트인지 표현해주는 변수 index
int index = 0; -
탐색 값과 대상의 값을 비교할때마다 indexr값 1씩 증가시키기
더이상 탐색 대상이 없다면 -1을 반환
while(temp.data != data){ temp = temp.next; index++; if(temp == null){ return -1; } } -
탐색 대상을 찾았다면 대상의 인덱스 값을 반환하기
return index;
전체코드
public int indexOf(Object data){
Node temp = head;
int index = 0;
while(temp.data != data){
temp = temp.next;
index++;
if(temp == null){
return -1;
}
}
return index;
}
참고 사이트
Leave a comment